4. OmniGraph 可视化逻辑开发¶
4.1 三层次来看X1仿真案例¶
在 X1 机器人复杂场景仿真中,为实现自主导航、目标识别与抓取等复合型任务,我们采用 “模块化拆分 - 独立实现 - 集成调度” 的三层架构思路,既保证每个功能模块的精准可控,又能通过协同机制完成整体任务。
4.1.1 Omnigraph完成独立模块¶
Omnigraph(ActionGraph)作为 Isaac Sim 的可视化逻辑编排工具,是实现单一功能模块的核心方式之一。其通过节点拖拽与连线的方式,可直观定义机器人的局部行为逻辑:
Articulation Controller(关节驱动): “关节控制节点” 驱动双臂的每个关节按预设轨迹运动
RTX LiDAR Sensor: “传感器数据读取节点” 获取相机识别到的零食位置
Transform Between Frames: “坐标转换节点” 将位置信息转化为机械臂的运动指令。
目前,基于 Omnigraph 已实现导航路径跟踪、相机图像采集与目标识别、双臂协同抓取等独立模块,且各模块可通过 ROS 接口与外部环境交互(如接收外部发布的目标点坐标,驱动导航模块执行)。这种可视化方式无需复杂代码编写,便于快速调试单一功能的逻辑正确性。
4.1.2 独立化脚本完成独立模块¶
独立化 Python 脚本是实现功能模块的另一种核心方式,其通过调用 Isaac Sim 与 ROS 的 API,以代码形式精确控制机器人的行为。
相较于 Omnigraph,脚本更适合处理需要复杂计算或动态决策的场景:例如在导航模块中,脚本可实时接收激光雷达数据,通过路径规划算法(如 A*)动态生成避障路径,并将关节控制指令直接发送至机器人底盘。
目前,基于脚本已实现导航模块的完整功能,支持根据外部发布的目标坐标自主规划路径、避开障碍物并抵达指定区域。这种方式灵活性更高,便于集成自定义算法(如优化的路径搜索逻辑),且代码可复用性强,适合需要频繁迭代的模块开发。
4.1.3 多阶段复合任务¶
当单一模块功能成熟后,需通过集成机制实现多模块的协同工作,完成 “导航 - 识别 - 抓取” 的全流程任务。目前主要采用两种集成思路:
第一种是 “手动分步执行” 模式,该模式主要为降低集成难度,适用于选手对各模块功能进行熟悉和调试阶段。具体操作流程为:选手通过手动触发的方式依次执行各个任务模块,例如,先手动启动导航模块,操作机器人从起点移动至目标区域,待机器人稳定停靠后,再手动触发相机模块进行拍照并完成目标识别,获取零食的位置信息后,最后手动启动双臂控制模块,驱动机械臂按识别到的位置完成抓取动作。这种方式无需复杂的自动化调度逻辑,每个阶段的任务执行都由选手主动控制,便于及时观察各模块的运行状态,排查单一模块可能出现的问题,为后续的自动化集成打下基础。
第二种是 “脚本化任务管理器” 模式,即通过一个主 Python 脚本作为中枢,按任务逻辑调度各独立模块:例如,主脚本先调用导航模块驱动机器人抵达目标区域,待导航完成后触发相机识别模块采集图像并解析零食位置,再将位置信息传递给双臂抓取模块执行抓取动作,全程通过状态变量监控各模块的执行进度,确保流程有序衔接。
通过三个关键维度拆解 X1 仿真案例:
先聚焦 Omnigraph 图形化编排能力,用可视化逻辑构建导航、视觉等独立功能模块(2.2);再延伸至 独立化脚本开发,以代码深度定制模块行为,突破图形化工具的灵活性边界(3.1);最终落地 多阶段复合任务,验证导航、视觉、机械臂协同作业的完整流程(3.2)。这三层递进,将帮你从 “单点功能实现” 过渡到 “复杂系统集成”,理解仿真技术如何支撑真实机器人任务落地 —— 下面,我们逐个拆解模块构建的具体方法。
小结:在搭建 X1 机器人仿真培训体系时,我们已明晰案例背景与核心逻辑。接下来,将从 “模块化实现” 到 “系统级集成” 深入展开。
4.2 独立模块实现(Omnigraph篇)¶
为什么用Omnigraph?
在 Isaac Sim 中用 Omnigraph 实现独立模块,核心是以可视化节点逻辑降本提效,适配快速验证、低代码需求场景,核心价值有三:
低代码快速搭建:无需写 Python/C++,拖拽预制节点(如关节控制、传感器采集、事件触发)并连线,就能快速实现模块功能。比如 10 分钟内可搭好 “检测目标→机械臂转动→夹爪抓取” 的完整逻辑,省去代码编写调试时间。
逻辑直观易调试:模块运行逻辑(如数据流向、指令触发顺序)以节点连线呈现,出现问题时(如未抓取成功),可直接查看节点信号是否传递,快速定位 “信号断连” 或 “逻辑缺失”,比逐行查代码更高效。
原生适配生态:节点与 Isaac Sim 物理引擎、传感器、机器人模型深度集成,比如摄像头节点可直接读仿真数据,无需额外写接口,能无缝对接其他 Isaac 工具,避免兼容性问题。
4.2.1 导航仿真案例¶
注意:因涉及初赛相关,该 Demo 资料暂不提供。选手可参考其运行思路与逻辑,自行实现导航模块。
4.2.1.1 ActionGraph导航整体思路¶
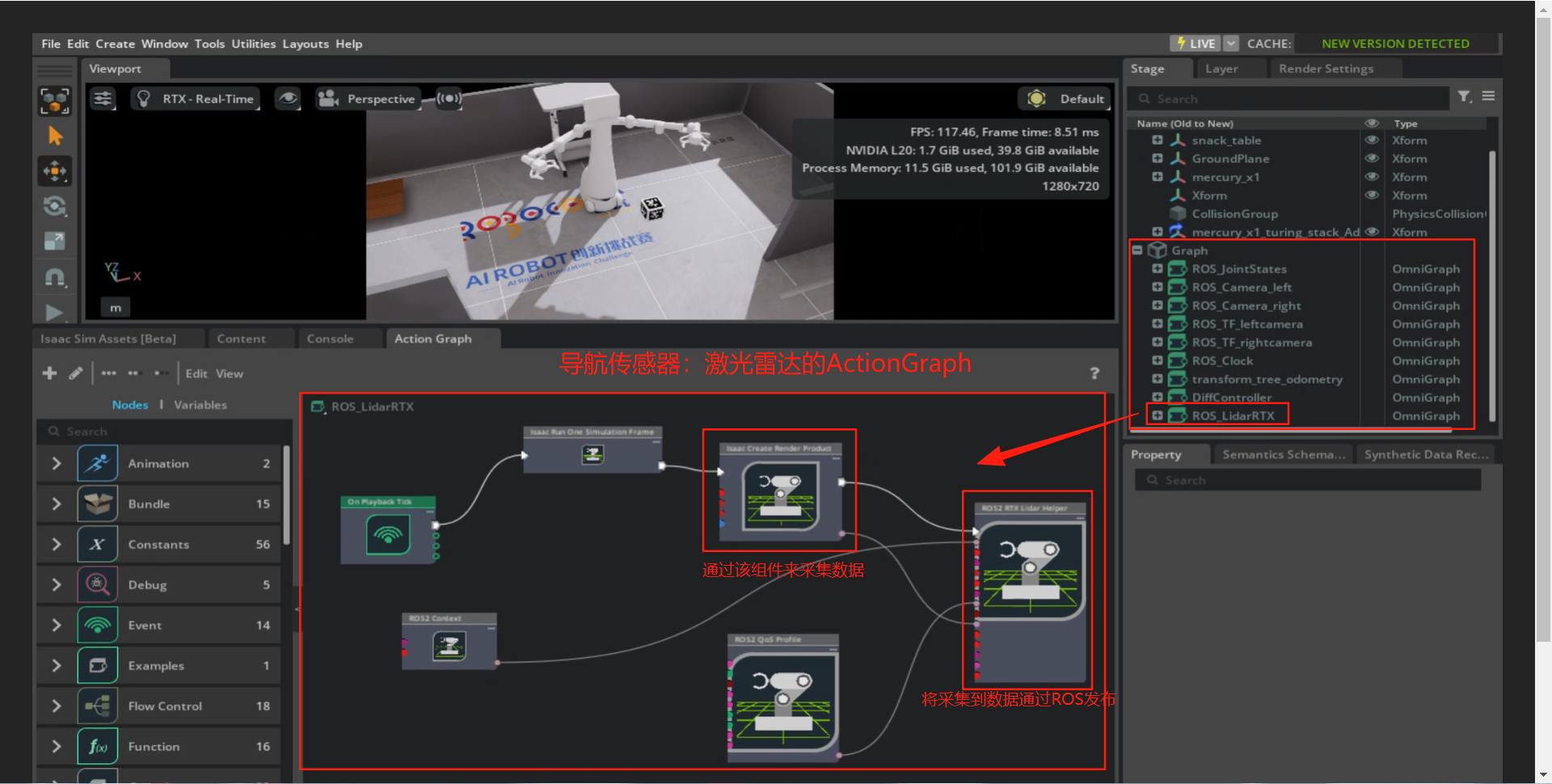
涉及硬件:X1机器人底盘与轮子、激光雷达、里程计
ActionGraph设计与实现:
- 激光雷达:导航的核心传感器:激光雷达的ActionGraph如下:
差速控制:对于底盘与轮子关节的控制
里程计与TF转换:
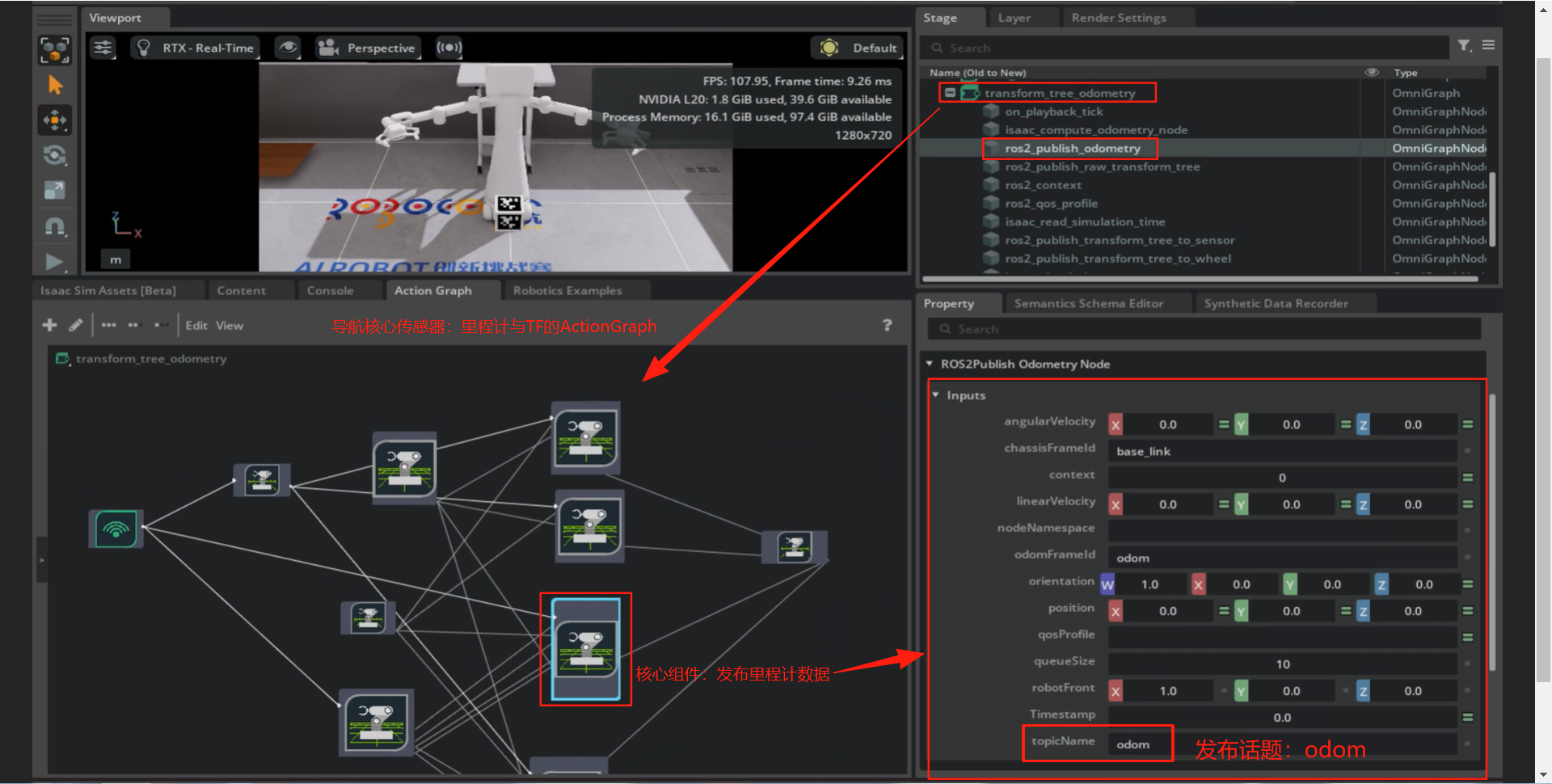
看上去挺复杂,其实明白其原理后会发现很简单,大部分都是重复的。
4.2.1.2 导航建图¶
注意:如果是使用我们提供的镜像,镜像中已经完成建图和环境配置,需要再次建图!
具体步骤
- 点击Tools>Robotics>Occupancy Map
舞台中选择prim(单击整个prim即可)
点击bound selection
设置0.62/0.1高(因人而异)
点击calculate
点击visualize image
出现建图弹窗:
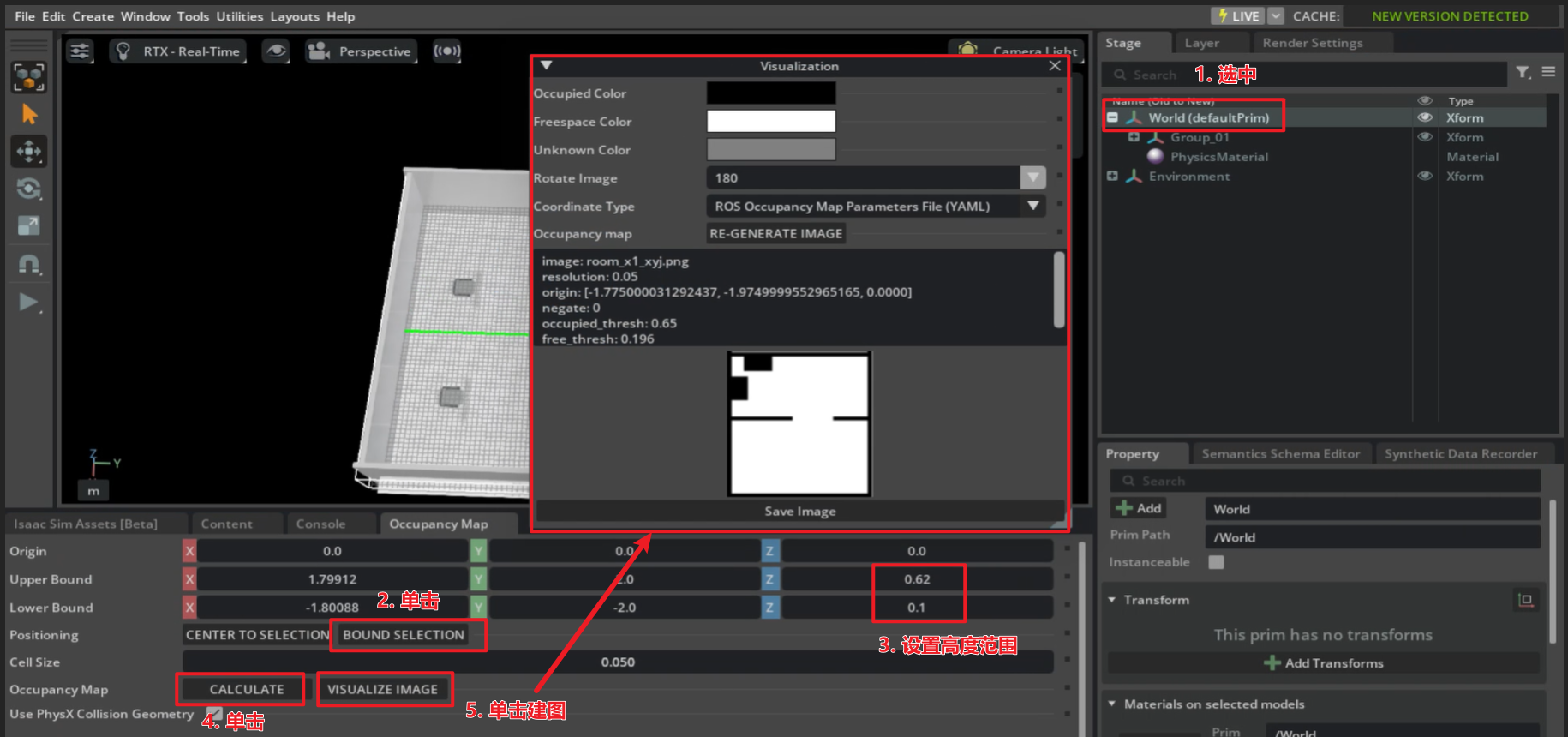
- 设置visualization参数:
(1)Rotate Image: 180
(2)Coordinate Type: ROS Occupancy Map Parameters File(YAML)
点击RE-GENERATE IMAGE
复制全文:
image:carter_warehouse_navigation.png
resolution:0.05
origin:[-11.975,-17.975,0.0000]
negate:0
occupied_thresh:0.65
free_thresh:0.196
- 点击Save Image保存图片
注意:以上操作教大家如何通过Isaac Sim建图,至于建图之后的操作,由于导航实现方式不一,需要大家参考课程来具体适配自己的情况。
- 替换导航功能包中的Yaml文件与Png图片:
(1)将刚刚复制的yaml文件代码粘贴并覆盖:/root/humble_ws/src/navigation/carter_navigation/maps/carter_warehouse_navigation.yaml
(2)将刚刚保存的png文件粘贴并覆盖:/root/humble_ws/src/navigation/carter_navigation/maps/carter_warehouse_navigation.png
到此建图流程完成了!接下来编译执行的命令参考以下:
流程:在 Isaac Sim 平台中进行数据采集,利用 SLAM 等算法生成地图,将生成的地图图片和配置文件导出并放入 ROS2 导航功能包中。
功能包结构与编译:导航功能包结构如
humble_ws/src/navigation/carter_navigation,包含launch、maps等目录。编译时需安装必要依赖(navigation2, cartographer, rviz2),使用colcon build --packages-select carter_navigation命令进行编译。功能包执行:请参考2.2.1.3 导航模块Demo执行。
4.2.1.3 导航模块Demo执行¶
该导航 Demo 重点讲解运行逻辑及 ActionGraph 与导航功能包的关系,任务较简单:从起点出发至二维码前方点位。
导航模块 Demo 的执行需按特定顺序操作,涉及仿真环境准备、功能包启动及底盘控制等环节,具体步骤如下:
4.2.1.3.1 步骤一:准备仿真环境¶
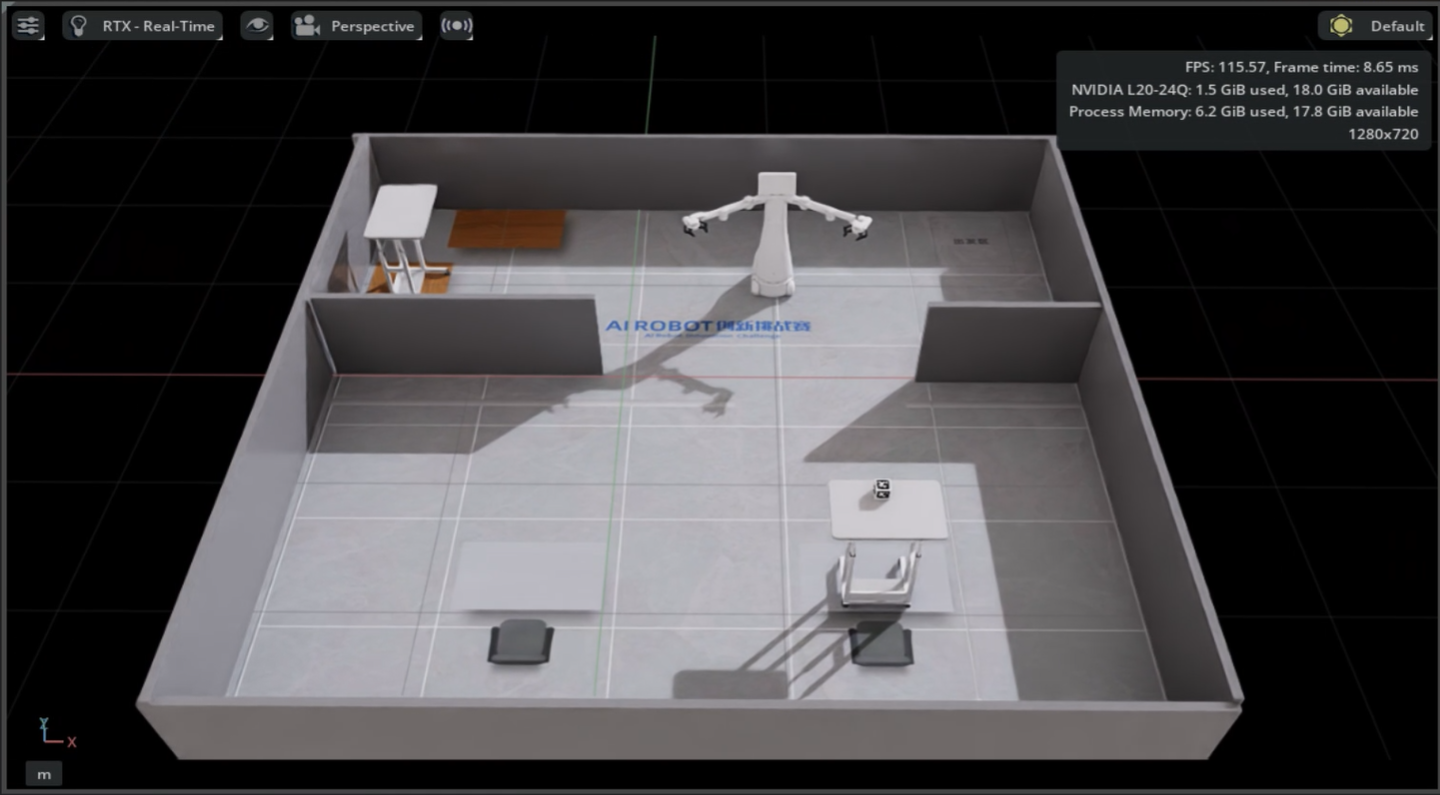
启动仿真容器,或启动我们提供的镜像文件。
在该容器中,打开指定的 USD 文件,路径为:isaac-sim/x1-manipulator/USD_Save/mercury_final_env_action.usd,加载导航所需的仿真场景。
4.2.1.3.2 步骤二:启动导航功能包¶
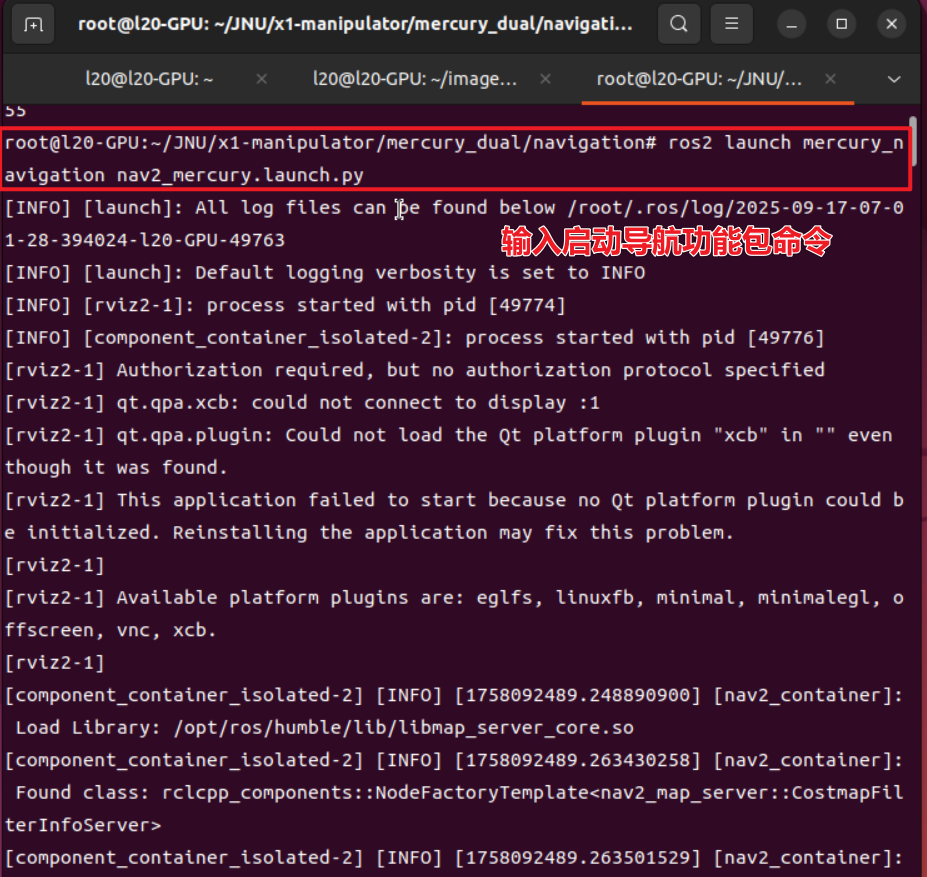
切换至容器 “ros2”(容器非必需,ros2环境即可)
进入目录:root/JNU/x1-manipulator/mercury_dual/navigation。
执行命令:source install/setup.bash,初始化环境。
接着执行命令:ros2 launch mercury_navigation nav2_mercury.launch.py,若启动过程无报错,则导航功能包成功启动。
4.2.1.3.3 步骤三:启动底盘控制与目标点发送¶
启动顺序严格遵循:先在 USD 文件界面点击 “play” 运行仿真,再启动上述导航功能包,最后通过以下任意一种方式启动底盘控制并发送目标点:
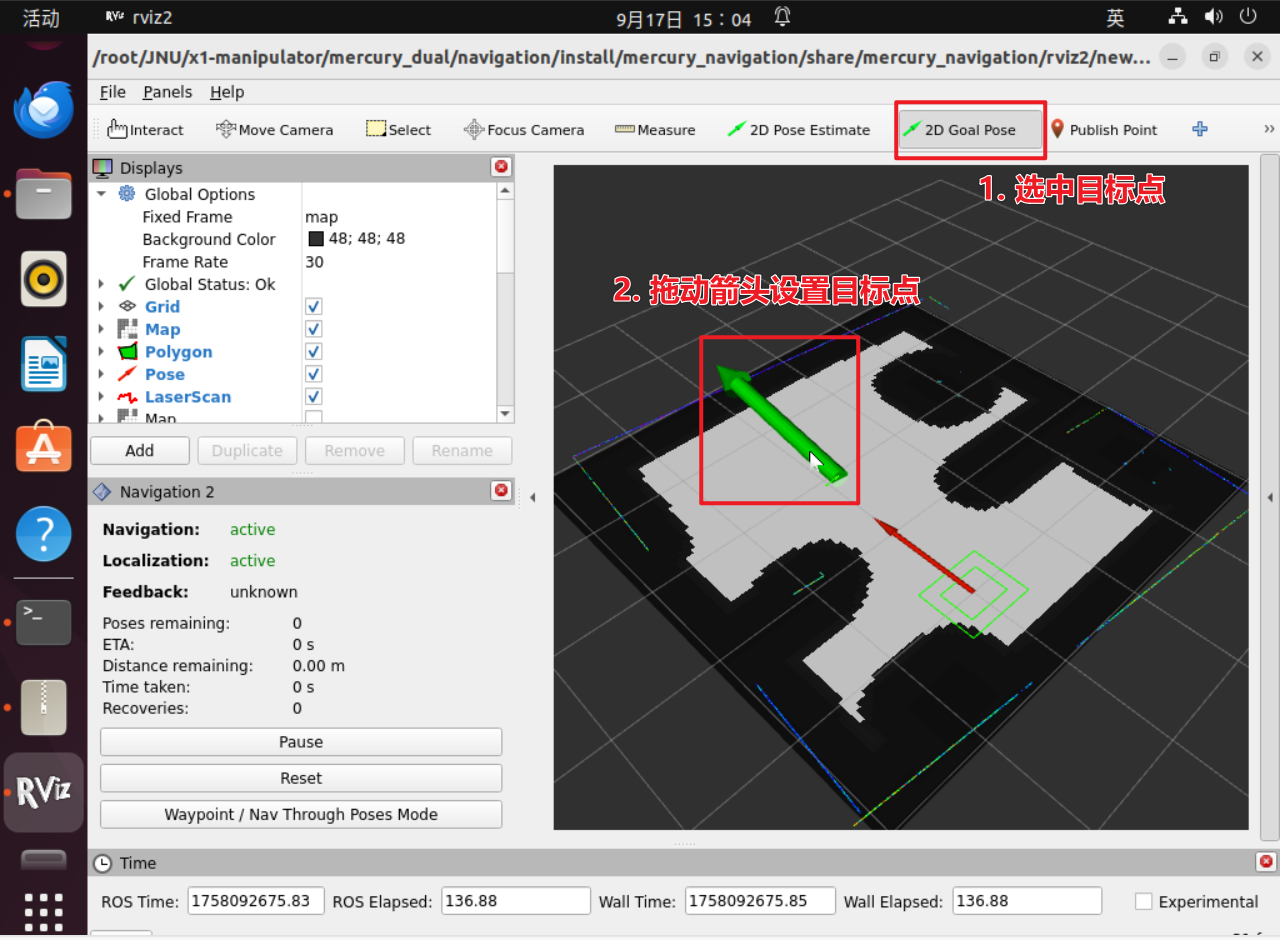
- 方式一:通过 RViz 设置目标点 在已启动导航功能包的基础上,打开 RViz 可视化工具。 在 RViz 界面中,通过交互工具手动指定机器人的目标点,目标点信息将自动发送至导航功能包,实现导航控制。
方式二:手动发布 ROS 话题 直接在终端发布目标点话题,有两种命令形式可选:
执行 action 命令:ros2 action send_goal /navigate_to_pose nav2_msgs/action/NavigateToPose "{ pose: { header: {frame_id: 'map'}, pose: { position: {x: -1.0, y: 1.0, z: 0.0}, orientation: {x: 0.0, y: 0.0, z: 1.0, w: 0.0} } } }"
执行 topic 命令:ros2 topic pub /goal_pose geometry_msgs/msg/PoseStamped "{ header: { stamp: {sec: 0, nanosec: 0}, frame_id: 'map' }, pose: { position: {x: -1.0, y: 1.0, z: 0.0}, orientation: {x: 0.0, y: 0.0, z: 1.0, w: 0.0} } }" --once
方式三:启动底盘代码 进入 perceptor 目录。 执行命令:python3 -m robot_chassis.chassis_ros,启动底盘相关代码,完成导航测试。
def execute(self, command: Command, callback=None):
"""处理上层命令,发送目标点并等待导航完成"""
try:
self.task_id = command.params.get("TASK_ID", 0)
params = command.params
if not isinstance(params, dict):
self.logger.errorlog(self.name, "参数格式错误,必须为字典")
return {"result": -1, "error": "invalid params"}
# 构造导航目标点 - 与ros2命令保持一致的结构
self.target_pose = PoseStamped()
self.target_pose.header.frame_id = "map" # 与命令中的frame_id保持一致
self.target_pose.header.stamp = self.ros_node.get_clock().now().to_msg()
# 设置位置参数,与命令中的x: -1.0, y: 1.0, z: 0.0对应
self.target_pose.pose.position.x = params.get("x", 1.0)
self.target_pose.pose.position.y = params.get("y", 0.2)
self.target_pose.pose.position.z = params.get("z", 0.0)
# 设置姿态参数,与命令中的x: 0.0, y: 0.0, z: 1.0, w: 0.0对应
self.target_pose.pose.orientation.x = params.get("qx", 0.0)
self.target_pose.pose.orientation.y = params.get("qy", 0.0)
self.target_pose.pose.orientation.z = params.get("qz", 1.0)
self.target_pose.pose.orientation.w = params.get("qw", 0.0)
self.callback = callback
self.active_goal_handle = None # 用于保存当前目标句柄
# 发送目标点并等待导航完成(通过动作客户端)
self._send_nav_goal_and_wait()
return
except Exception as e:
return {"result": -1, "error": str(e)}
两种命令均可将目标点信息发送给导航功能包,驱动机器人前往指定位置。

通过上述步骤,可完成导航模块 Demo 的执行,验证机器人在仿真环境中自主前往目标点的功能。
4.2.2 视觉仿真案例-双目篇¶
4.2.2.1 整体实现思路¶
视觉仿真案例的核心是构建 “仿真环境数据采集-外部算法处理-目标位姿输出” 的闭环流程,具体实现思路如下:
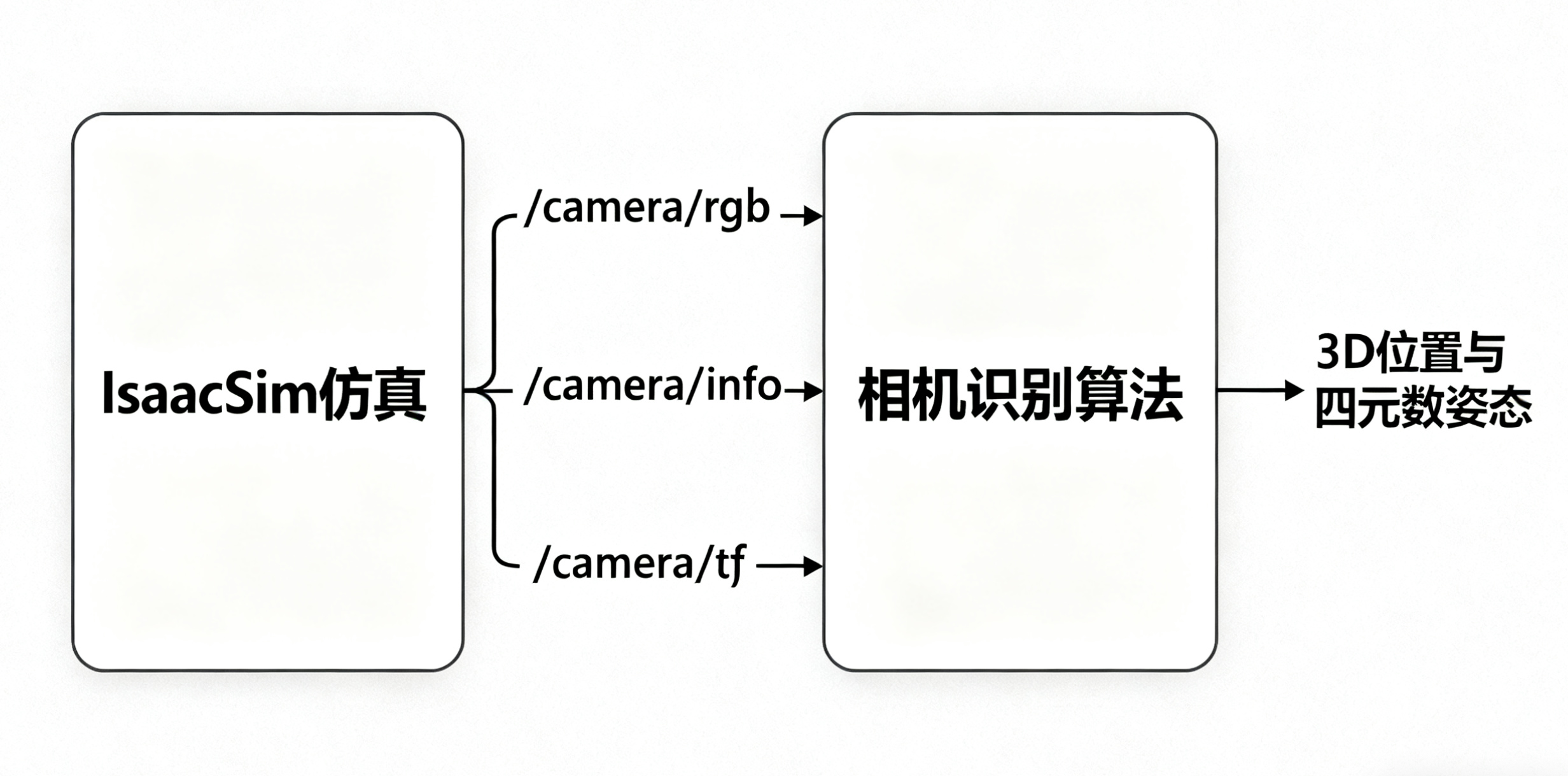
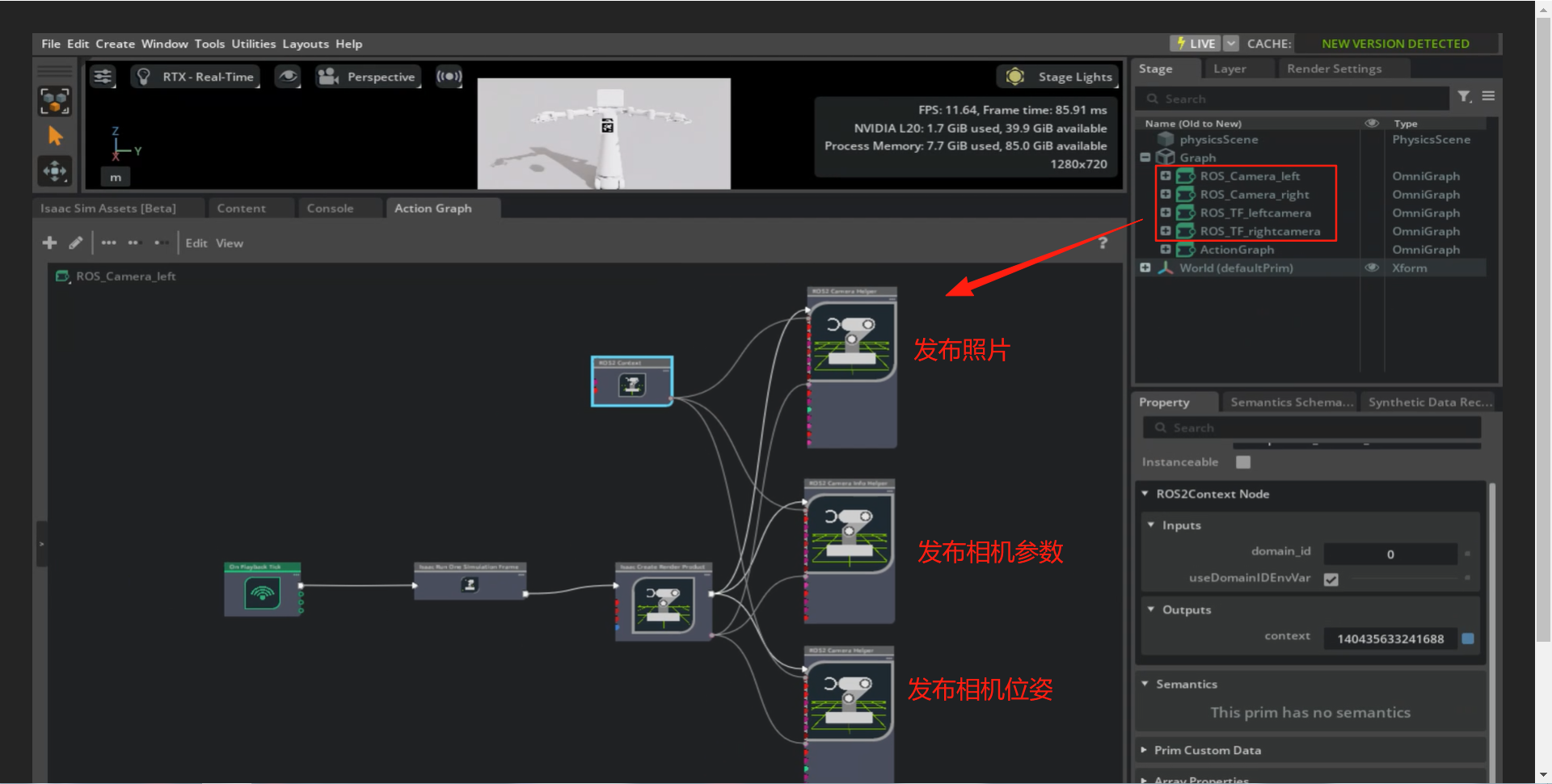
在Isaac Sim仿真环境中,通过ActionGraph可视化逻辑编排工具完成视觉数据的采集与发布:首先,通过相机节点触发图像拍摄,同步获取当前相机的位姿信息(位置与姿态)及内参矩阵(包含焦距、光学中心等参数);随后,借助ROS接口节点将图像数据、相机位姿、内参矩阵等信息封装为ROS话题(如/camera/rgb、/camera/info、/camera/tf等)并对外发布。
在外部ROS环境中,通过编写核心处理脚本订阅上述话题数据:将接收的图像作为识别算法的输入源,结合相机内参完成畸变校正与坐标转换,通过二维码检测算法识别目标并提取像素坐标;最终,基于相机位姿与像素坐标解算目标二维码在世界坐标系下的三维位置(position)和姿态(四元数),为后续机器人抓取等操作提供精准的定位依据。
整个流程通过ROS实现仿真环境与外部算法的高效通信,既利用Isaac Sim的高保真仿真能力复现真实视觉场景,又通过外部算法部署保留了算法迭代的灵活性。
4.2.2.2 理解相机¶
4.2.2.2.1 双目相机的结构与工作原理¶
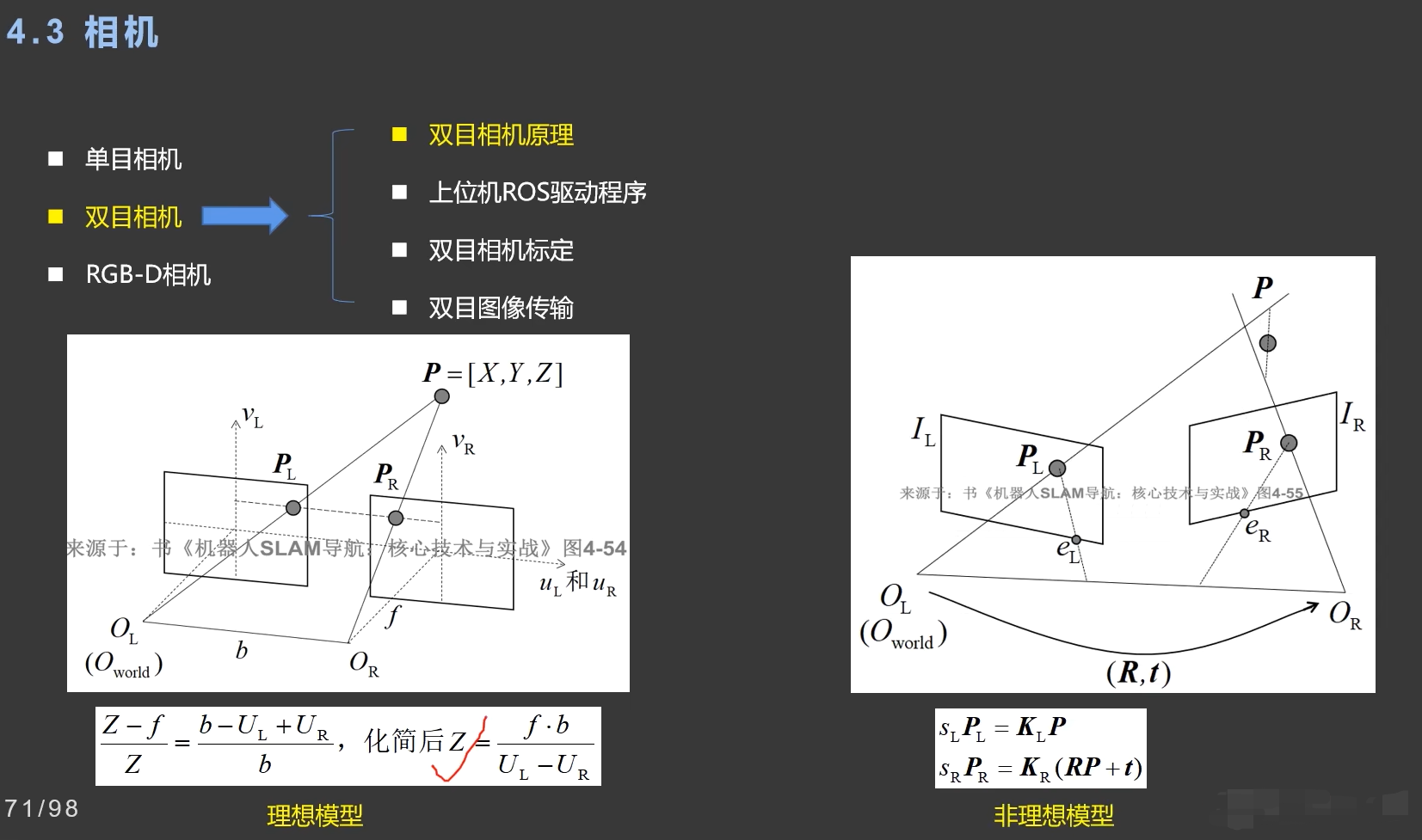
双目相机由两个相机组成,两个相机之间的距离称为基线。通过两个相机同时拍摄同一物体,可以获取物体的立体信息。
双目相机的工作原理基于三角测量法。当两个相机同时拍摄同一物体时,由于两个相机的位置不同,物体在两个相机图像中的位置也会不同。通过计算物体在两个图像中的位置差异(视差),结合相机的内参和外参,就可以计算出物体到相机的距离。
与单目相机相比,双目相机具有以下优势:
- 深度感知能力:能够计算得到深度信息,为机器人提供更丰富的环境感知。
- 精度高:在一定范围内,双目相机的深度测量精度较高。
- 适应性强:对光照变化和物体表面纹理的适应性较强。
下图是理想与非理想状态下的双目相机的原理:
4.2.2.3 AprilTag 检测与识别¶
4.2.2.3.1 AprilTag 简介与原理¶
AprilTag 是一种基于计算机视觉的 fiducial marker(基准标记)系统,由密歇根大学的 Matthew Kaess 等人开发。与传统的二维码相比,AprilTag 专为机器人视觉和增强现实应用设计,具有以下特点:
- 高精度定位:能够提供亚像素级的角点检测精度
- 高鲁棒性:在部分遮挡、光照变化等条件下仍能稳定检测
- 快速识别:适合实时应用场景
- 编码容量:通过不同的图案设计支持多种 ID 编码
Tags是由黑白相间的类似于二维码的方块构成,不同的Tag包含了不同的ID信息

其核心原理是通过检测图像中的特定黑白方块图案,计算图案的角点坐标,再结合相机内参和位姿信息,将 2D 图像坐标转换为 3D 世界坐标。
4.2.2.3.2 AprilTag 检测模块¶
该模块实现了从图像中检测 AprilTag 并计算其像素位置的功能,主要流程包括:
- 图像预处理:将彩色图像转换为灰度图,减少计算量并提高检测稳定性
- 字典与参数配置:使用 OpenCV 内置的DICT_APRILTAG_36h11字典,该字典包含 36 位编码,支持 11 位唯一 ID
- 角点检测:通过cv2.aruco.detectMarkers函数检测图像中的 AprilTag,返回角点坐标和 ID
- 中心计算:对四个角点坐标取平均,得到 Tag 的像素中心位置
- 结果可视化:在原图上标记角点和中心,便于直观验证检测效果
4.2.2.3.3 AprilTag 坐标系转换¶
从像素坐标到三维世界坐标的转换,涉及计算机视觉中的坐标变换理论:
视差计算:获取双目相机左右图中 Tag 四个角点的像素坐标,计算每个角点的视差d = u - u'
视差公式:d = u - u'(其中 u 为左图像素的 x 坐标,u' 为右图对应像素的 x 坐标,y 坐标理论上一致,因双目相机已完成校正)。
深度值推导:利用双目相机的基线距离(B,左右相机光心间距)和焦距(f,像素单位),通过三角测量原理计算每个角点的深度值(Z):
深度公式:Z = (B * f) / d。 对四个角点的深度值取平均,作为 Tag 中心的最终深度值,减少单一点位误差对结果的影响。
相机坐标系转换:结合左相机内参(cx, cy 为光学中心坐标,fx, fy 为焦距的物理单位转换值),将左图中 Tag 中心的像素坐标(u0, v0)与计算出的深度值 Z 结合,反投影至相机坐标系(Xc, Yc, Zc):
视差公式:d = u - u'(其中 u 为左图像素的 x 坐标,u' 为右图对应像素的 x 坐标,y 坐标理论上一致,因双目相机已完成校正)。
4.2.2.3 Apriltag识别核心代码¶
detect_aprilTag方法旨在识别图片中二维码,并返回四个角点的坐标以及中心点坐标。后续则是左右相机分别识别的四个角点坐标通过“视差”计算深度值。
def detect_aprilTag(self, rgb_img=None, show_result_img = False):
#添加图像输入校验
if rgb_img is None:
self.get_logger().warn("未输入图像,无法检测AprilTag")
return None, None # 明确返回None
# 把彩色图转换为灰度图,有时对检测更稳定
gray = cv2.cvtColor(rgb_img, cv2.COLOR_BGR2GRAY)
dictionary = cv2.aruco.getPredefinedDictionary(cv2.aruco.DICT_APRILTAG_36h11)
parameters = cv2.aruco.DetectorParameters()
corners, ids, rejected = cv2.aruco.detectMarkers(gray, dictionary, parameters=parameters)
......
return tag_corners, [int(center_u), int(center_v)]
4.2.2.4 ActionGraph实现¶
该案例通过Isaac Sim仿真的ActionGraph实现发布订阅仿真视觉数据,外部识别算法识别与目标点输出。
下图通过发布者(发布照片、发布相机相关参数),通过特定的ros话题名,外界ros订阅到该信息后,作为识别算法的输入。
小结: 整体实现效果如下动图:

步骤一:仿真Isaac Sim平台>点击play(此时ActionGraph随之启动,意味着关节订阅者开始订阅)
步骤二:执行Python脚本,其中核心代码如课程所示
补充:因为目前算法实现识别获取仅目标表面,而非中心点,因此(x,y,z)的x会有几厘米(边长的一半)的误差。
4.2.3 视觉仿真案例-深度篇¶
4.2.3.1 整体实现思路¶
深度视觉仿真案例的核心是构建 “仿真环境RGB-D数据采集-外部YOLO智能算法处理-无标记目标3D信息输出” 的闭环流程,摒弃传统AprilTag人工标记依赖,实现通用物体自主感知定位,具体实现思路如下:
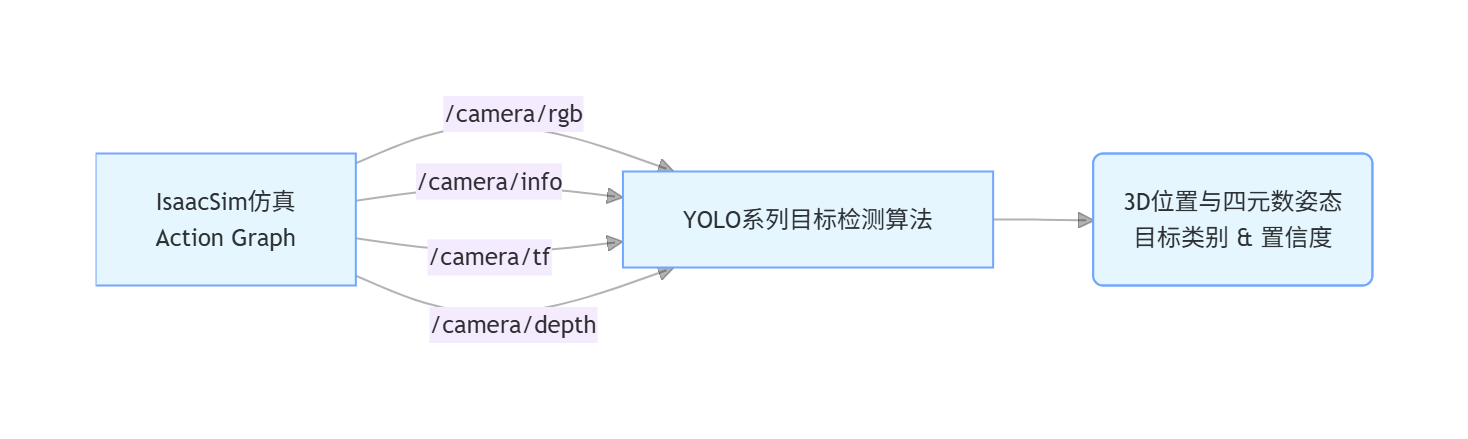
在Isaac Sim仿真环境中,沿用双目篇ActionGraph可视化逻辑编排框架,完成深度相机RGB图像、深度图像、相机位姿及内参矩阵的同步采集与发布;通过相机节点同步触发画面采集,依托ROS接口节点将RGB图、深度图、相机内参、TF位姿等信息封装为标准ROS话题对外发布。
在外部ROS环境中,订阅仿真端下发的图像与参数数据:将RGB图像送入YOLOE检测模型完成目标识别,输出物品种类、检测框、置信度与2D像素坐标;结合深度图像素级深度信息或双目视差原理,解算目标在世界坐标系下的三维位置与姿态,无需粘贴任何辅助标记,即可为机器人抓取、分拣、避障等任务提供可靠感知输入。
整套流程保留Isaac Sim高保真仿真与ROS分布式通信优势,以深度学习检测替代传统标记识别,完成从专用标记定位到通用智能视觉的技术升级。
4.2.3.2 理解相机¶
4.2.3.2.1 深度相机的结构与工作原理¶
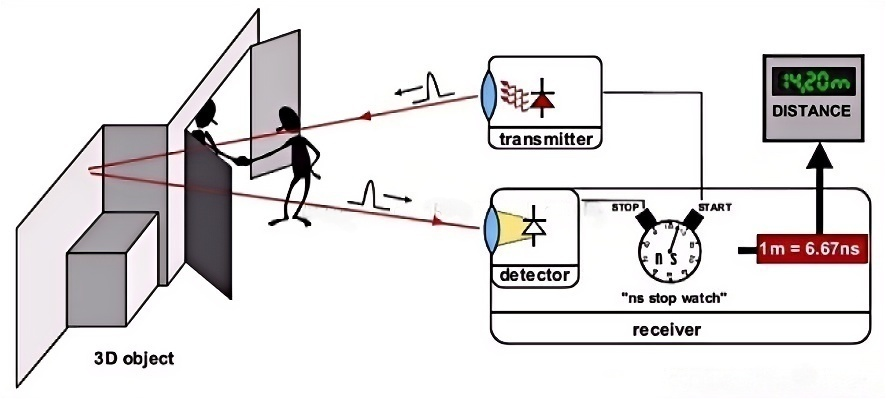
深度相机也叫RGB-D相机,集成RGB彩色成像模块与深度感知模块为一体,可同时输出彩色图像与像素级深度信息。常见技术方案包含ToF飞行时间、结构光等。
深度相机工作原理:通过主动发射红外光并接收回波信号,直接测算相机光心到场景每一个像素点的直线距离,硬件层面直接生成深度图,无需依靠双目视差、三角测量等算法间接计算深度。
相比单目、双目相机,深度相机核心优势:
- 即插即用深度:直接输出深度值,无需标定、无需视差解算
- 无标记识别:支持任意自然物体检测,不依赖二维码、AprilTag
- 同步性高:RGB图像与深度图像硬件时间戳对齐,适配实时机器人控制
- 部署简单:单设备即可完成3D感知,无需双相机基线调试
4.2.3.3 YOLO系列检测模型¶
4.2.3.3.1 YOLOE检测模型¶
YOLOE是YOLO系列轻量化增强版本,专为嵌入式机器人、边缘设备、仿真场景优化,具备推理速度快、参数量小、检测精度高的特点,非常适合部署在算力受限的机器人开发平台。
4.2.3.3.2 YOLOE的原理介绍¶
YOLOE属于One-Stage单阶段检测架构,无需候选框筛选,端到端直接回归目标类别、置信度与检测框坐标;采用轻量化骨干网络与特征融合结构,在保证检测精度的同时大幅降低算力消耗,满足机器人视觉实时性要求。
核心价值在于脱离人工标记物,可自主识别箱体、零件、物料等任意训练类别物体,彻底解决AprilTag必须贴标才能识别的行业痛点。
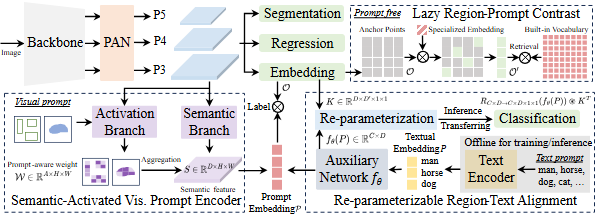
4.2.3.3.3 YOLOE的使用¶
与仿真平台联调过程中,ActionGraph的配置逻辑与双目篇完全保持一致。从整体技术架构层面来说,我们用YOLOE智能检测方案替代了传统Apriltag标记识别方案,以更智能、更通用的技术路径,大幅拉高了机器人视觉识别的应用上限与场景适配能力。
文本提示允许您通过文本描述指定希望 detect 的类别。以下代码展示了如何使用 YOLOE 在图像中 detect 人和公共汽车:
from ultralytics import YOLOE
# Initialize a YOLOE model
model = YOLOE("yoloe-26l-seg.pt") # or yoloe-26s/m-seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
model.set_classes(["person", "bus"])
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
接着把相应的results打印出来:
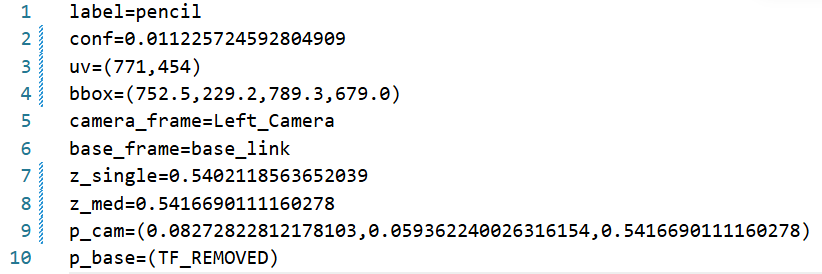
4.2.3.4 整体技术架构优化¶
我们不妨从架构视角做逐层分析:
- 做技术研发不能只埋头死磕单一模块,更需要拉高全局视角,以架构师思维梳理整套视觉方案的设计逻辑与迭代方向。
- 项目初期我们采用双目相机+Apriltag+视差算法的组合,能够实现规则物料的定点识别与三维坐标输出。
- 但该方案存在致命局限性:所有目标物料都需要人工粘贴专用标记码,依赖物理标识的模式,让机器人视觉无法走向真正的自主智能化落地。
- 站在架构设计角度,结合工业主流应用生态发现:YOLO系列算法是通用物体视觉识别的首选方案,因此我们舍弃传统Apriltag标记检测模式,切换为基于深度学习的YOLO智能识别架构。
- 方案输入:RGB-D深度图像 + YOLO目标检测模型
- 方案输出:目标物品种类、三维世界坐标、检测置信度等完整感知信息
- 同时考虑硬件兼容性做架构闭环:并非所有机器人都标配深度RGB-D相机,由此进一步迭代出双目相机+YOLO+视差算法的兼容方案,补齐无深度相机场景下的视觉感知能力。
4.2.3.4.1 双目相机+YOLO¶
细心的读者应该发现X1机器人并没有深度相机,仅有双目相机,该如何结合YOLO是一个核心关键部分。
在深度相机+YOLO的理想方案之外,我们也需要为硬件受限的场景提供兼容路径。继续以课程中的X1机器人为例,在轻量级YOLO算法不可替换、且硬件仅搭载双目相机的限制下,我们可以基于已学的双目视觉原理,迭代出低成本无标记3D定位方案。
该方案的核心,是复用双目篇中讲解的三角测量法(相似三角形原理),结合YOLO目标检测完成无标记视差计算:深度公式 $Z = \frac{B \times f}{d}$ 依然成立,区别在于——此前AprilTag为我们提供了目标角点的像素坐标,现在则由YOLO模型直接输出目标检测框的中心坐标,以此计算左右视图的视差 $d$,进而解算目标深度值。
4.2.3.4.2 整体思路¶
通过双目相机左右各拍一张RGB图片交给YOLO模型去标注,分别得到带有物料标注框的左右RGB图和2D坐标。 将左右标注框中心2D坐标放进视差公式中,可得到深度值z 最后将深度值z+左/右RGB图内参坐标换算,可以推算得到3D世界坐标。
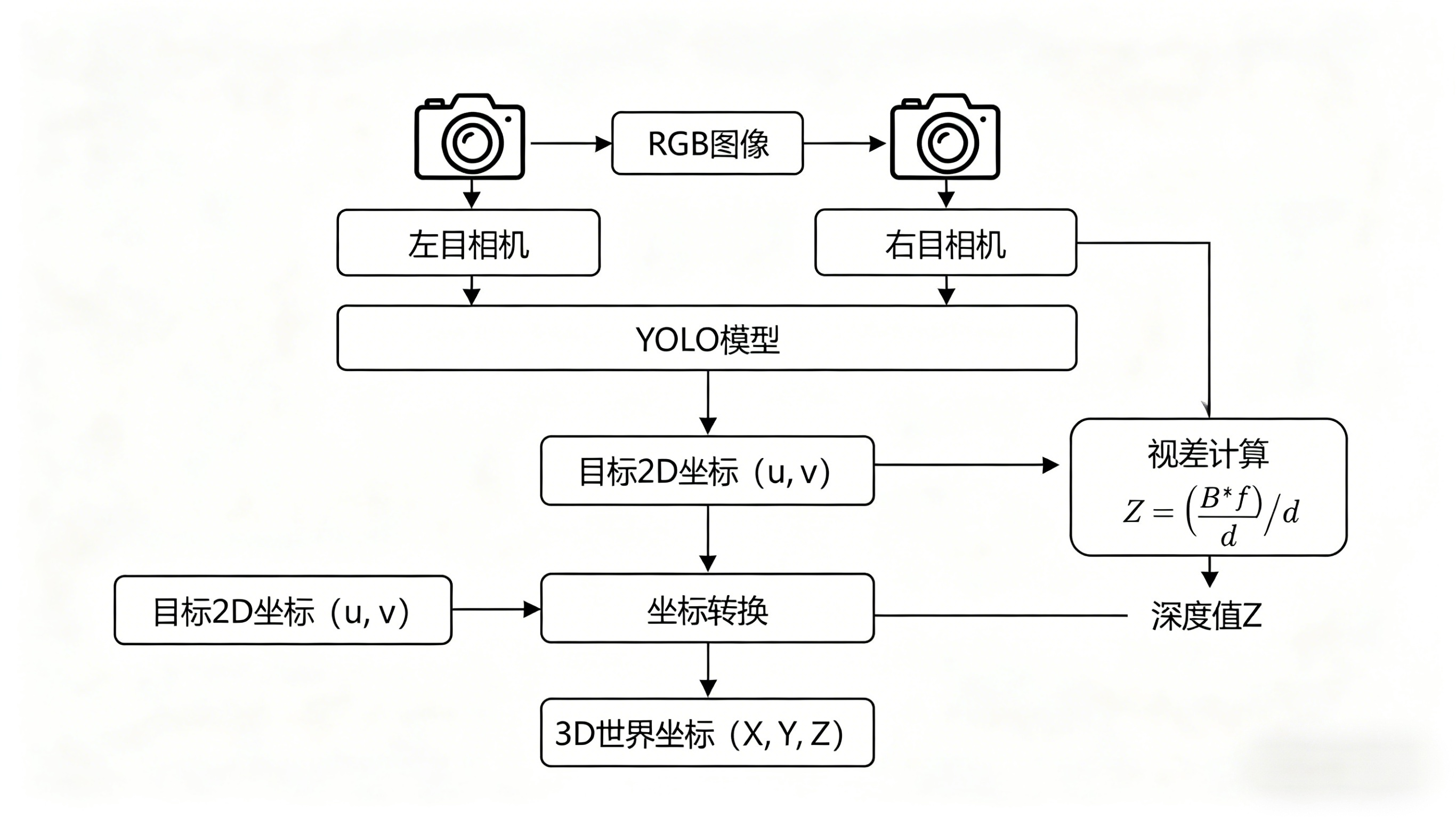
4.2.3.4.3 实现效果¶
双目相机+YOLOE无标记3D定位方案的完整仿真实现效果如下:

- 步骤一:启动Isaac Sim仿真平台,点击
play运行仿真,ActionGraph自动启动并同步发布双目相机的左右RGB图像、相机内参与TF位姿信息。 - 步骤二:运行YOLOE目标检测与3D定位脚本,订阅ROS话题并加载笔类目标检测模型。
- 步骤三:模型实时识别仿真场景中机器人前方的笔,输出目标检测框、类别与置信度;同时基于左右视图的目标中心坐标计算视差,解算出笔的三维世界坐标,完成无标记目标的定位。
补充说明:本方案彻底摆脱了AprilTag等人工标记物的依赖,仅通过双目相机与YOLOE模型即可实现通用物体的3D定位。视频中可清晰看到,模型能稳定识别不同角度、光照条件下的笔,笔的定位误差可控制在厘米级,满足机器人抓取任务的精度要求;相比传统标记方案,无需提前为目标粘贴专用标记,大幅提升了场景通用性与实际部署效率。
4.2.3.4.4 优劣势分析¶
对比双目+AprilTag、深度相机+YOLO、双目相机+YOLO三种方案,从定位精度、性能损耗、硬件成本、通用性、部署难度多维度对比分析:
| 对比维度 | 双目相机+AprilTag | 深度相机+YOLO | 双目相机+YOLO |
|---|---|---|---|
| 定位精度 | 高,亚像素级标定 | 高,像素级原生深度 | 中等,受视差匹配误差影响 |
| 性能损耗 | 极低,仅灰度检测与角点计算 | 中等,模型推理+深度解析 | 较高,双图推理+视差运算 |
| 硬件成本 | 中等,双目常规硬件 | 偏高,专用RGB-D深度相机 | 低,复用现有双目硬件 |
| 场景通用性 | 极差,必须粘贴专用标记 | 极强,无标记通用物体识别 | 强,无标记通用识别 |
| 部署维护 | 简单,算法轻量易调试 | 中等,需模型训练与部署 | 较复杂,需双目标定与匹配调参 |
| 适用场景 | 教学实训、固定工位标定 | 工业落地、通用抓取、场景感知 | 老旧硬件改造、低成本替代方案 |
核心总结: 1. 双目+AprilTag:适合课程教学、入门原理学习,无法落地真实工业场景; 2. 深度相机+YOLO:工业主流最优方案,兼顾精度、通用性与实时性; 3. 双目相机+YOLO:无深度相机硬件下的折中迭代方案,低成本实现无标记3D视觉。
4.2.4 双臂仿真案例¶
4.2.4.1 整体实现思路¶
将物理检查器调试的关节角度记录下来,存储到msg中,通过ros话题机制发布给仿真Isaac Sim的ActionGraph订阅者,即可实现控制双臂。
4.2.4.2 Physics Inspector物理检查器¶
这个工具主要用于查看和编辑场景中物体的物理属性(如质量、碰撞体、关节参数等),是调试物理仿真效果的常用工具。通常我们可以通过该工具,来测试机械臂关节角度,非常适合初学者。
- Tools>Physcis>Physcis Inspector,打开物理检查器。
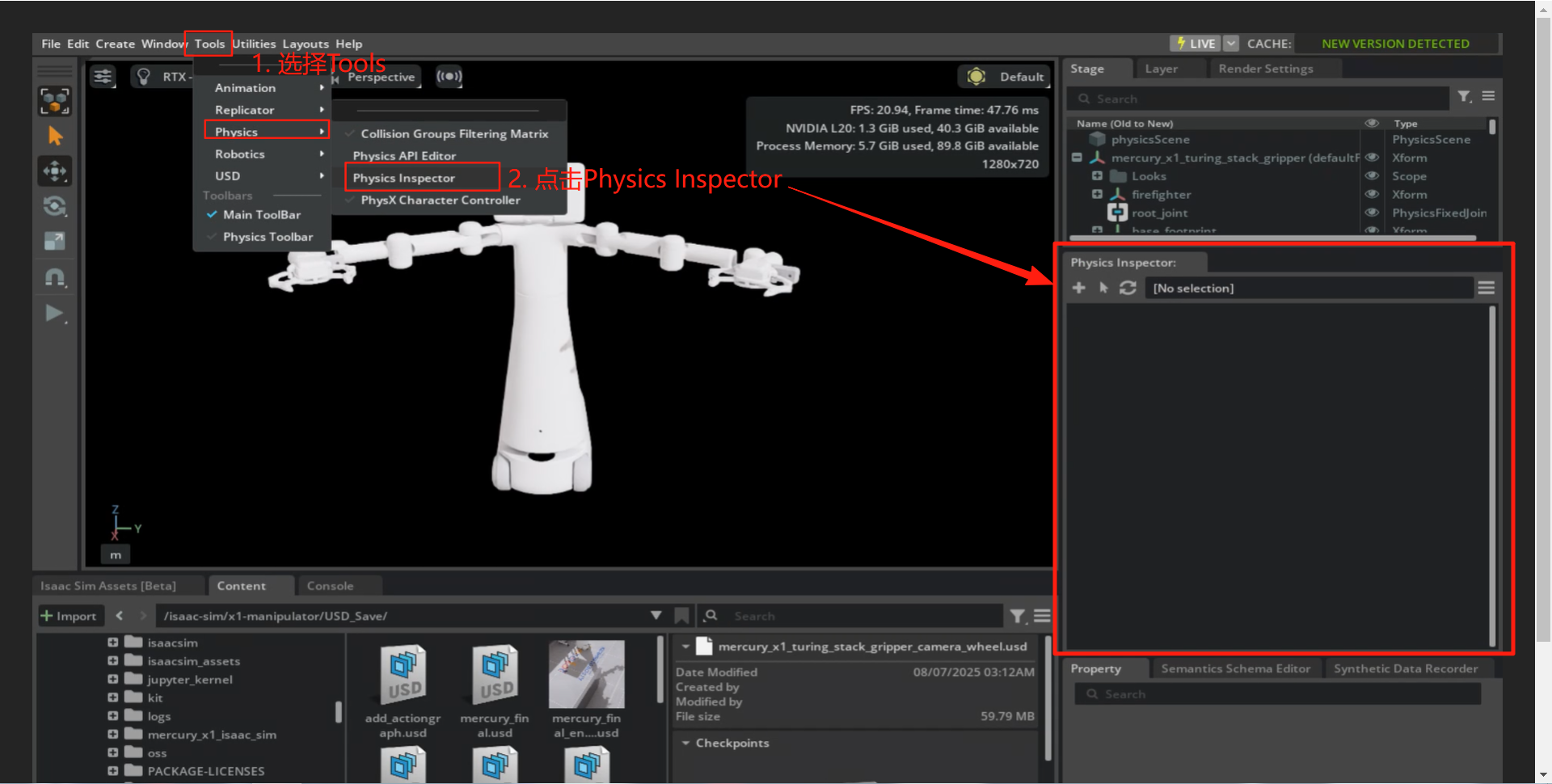
- 箭头>选择Prim>点击select,选中调试的机器人
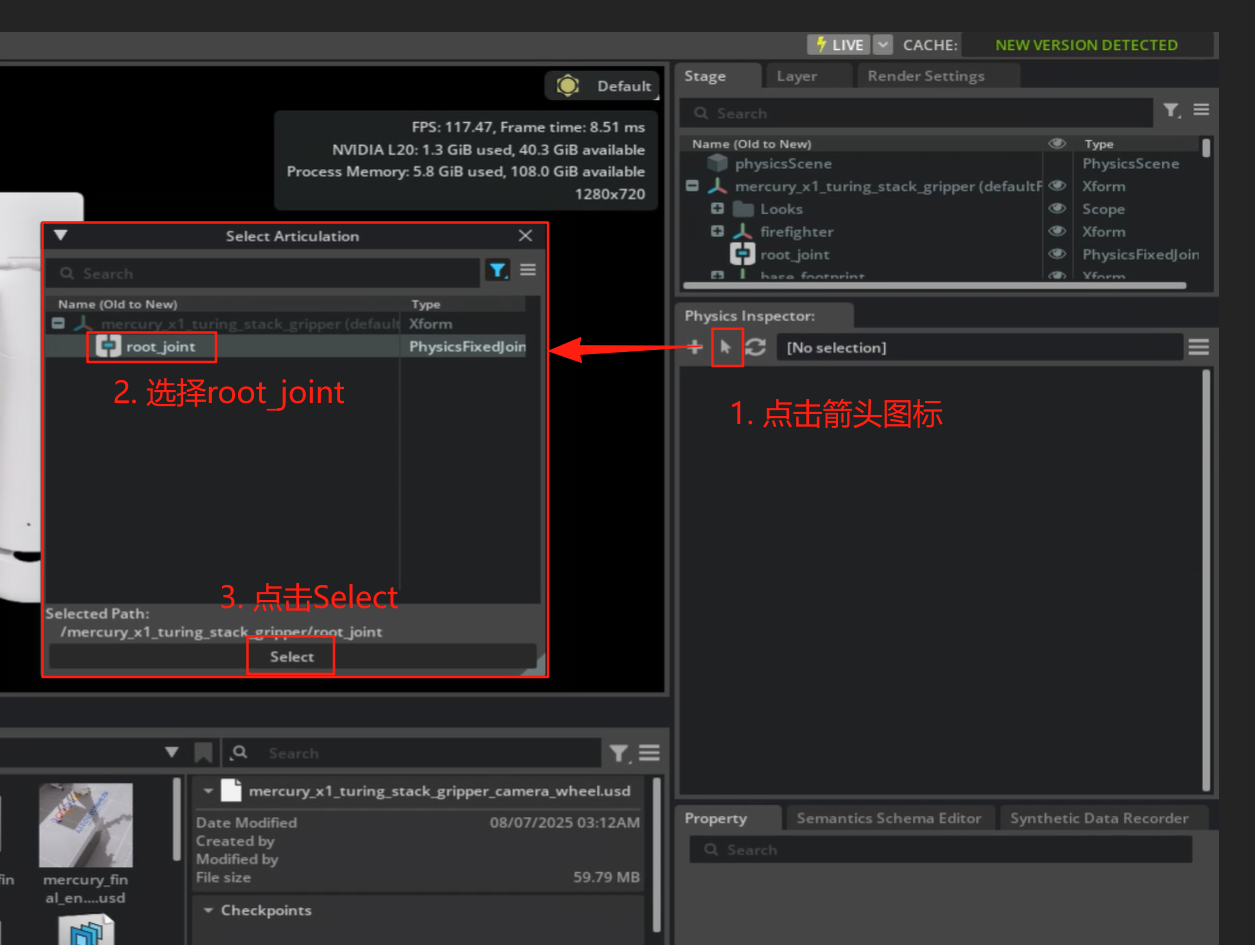
- 调试效果如下动图:

4.2.4.3 ActionGraph实现¶
下图通过关节控制器来控制仿真X1机器人的双臂,作为输入的组件是订阅者,其订阅话题名为:“joint_command”,话题信息则是外界ros发布的关节角度数组。
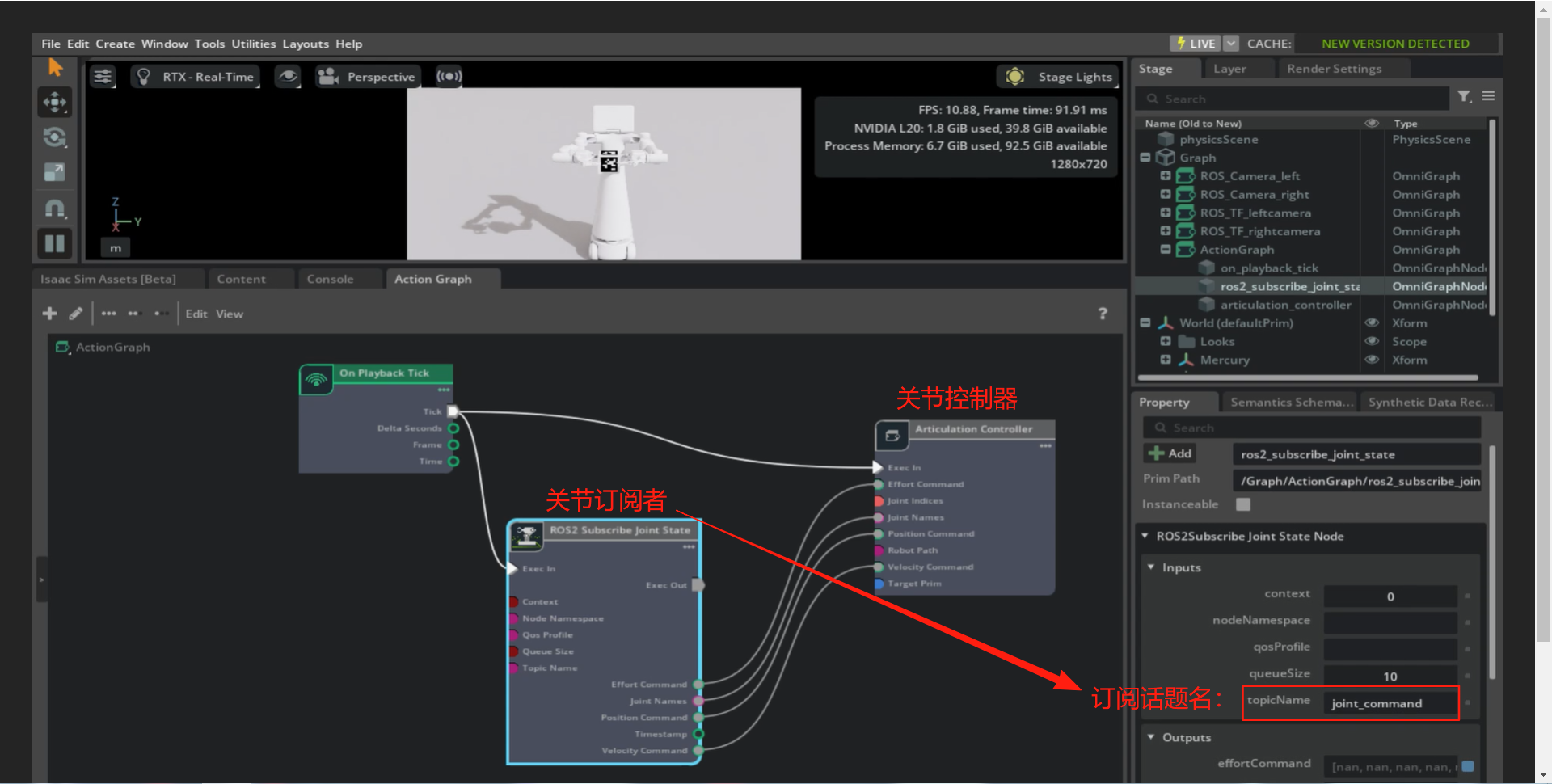
4.2.4.4 ROS实现¶
这是ROS2 发布话题数据的核心代码:
# 初始化订阅者,话题名与ActionGraph的发布者对应
self.joint_publish = self.create_publisher(JointState, "joint_command", 10)
# 初始化msg消息,将记录的关节角度输入msg中,发布“发布者”
def _publish_joint(self):
'''每次发布一个轨迹点'''
if not rclpy.ok() or self.stop_event.is_set():
return
msg = JointState()
msg.header.stamp = self.get_clock().now().to_msg()
msg.name = [
"joint1_L",
"joint2_L",
"joint3_L",
"joint4_L",
"joint5_L",
"joint6_L",
"joint1_R",
"joint2_R",
"joint3_R",
"joint4_R",
"joint5_R",
"joint6_R",
]
# 即将发布的关节角度数组(单位:弧度)
msg.position = [0.0, 1.0088, 0.0, 0.0, 0.0, 0.0, 0.0, 0.9128, 0.0, 0.0, 0.0, 0.0]
self.joint_publish.publish(msg)
小结: 整体实现效果如下动图:

步骤一:仿真Isaac Sim平台>点击play(此时ActionGraph随之启动,意味着关节订阅者开始订阅)
步骤二:将记录的关节角度转化成弧度,填入msg.position
步骤三:执行Python脚本,其中核心代码即2.2.3.4代码